Due to the nature of our research, most of our experiments are run in compute-intense environments - such as big shared-memory or distributed systems. While in some cases well-known research clusters (e. g. at HLRN or LRZ) are used for the computations, the majority of the results is obtained by using our own cluster - located at Humboldt-Universität zu Berlin. In order to support/improve reproducibility, we list here the current configuration of the system. We hope that, if you want to rerun the experiments on your own, this gives you a better understanding of our results and simplifies the assessment of your results.
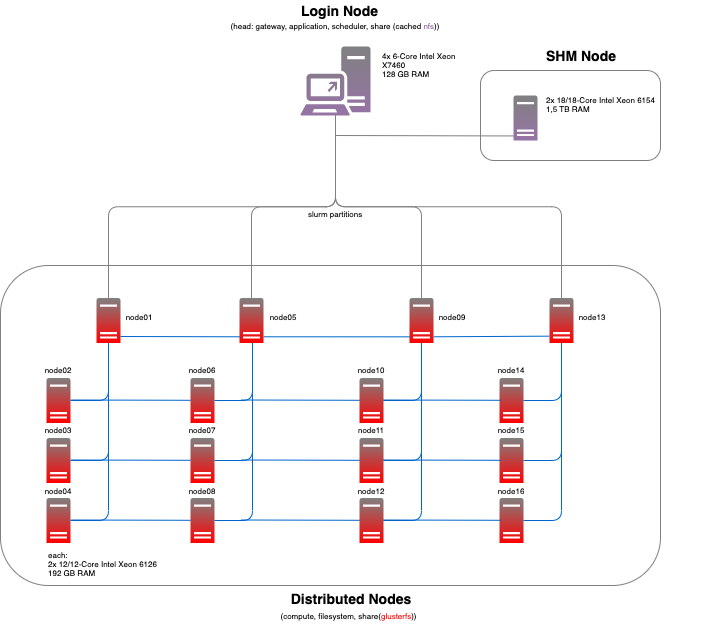
Specifications Head Node:
4x 6-Core Intel Xeon X7460
128 GB RAM
350 GB HDD (5x Raid-6 HDD)
2x10 Gbit bond LAN
Specifications SHM Node:
2x 18-Core Intel Xeon 6154
Disabled Hyperthreading
Disabled security mitigations
Driver: intel_pstate
disabled all C-states >= C1
active C0/P0-state
Permanent Boost-Clocks on all cores:
(scalar parallel code) 3.700 MHz
(vector parallel code, AVX2) 3.300 MHz
(vector parallel code, AVX512) 2.700 MHz
\(FLOPs_{node} = 3.11 \text{ TFLOPs}\)
24x 64 GB = 1,5 TB RAM (1,49 TB RAM usable for computation)
DDR4 2666 MT/s, Quad-Rank (NUMA balanced)
8,2 TB HDD (5x Raid-5 HDD, 2x Raid-1 SATA SSD)
1x10 Gbit LAN (Distributed File System, Management)
Specifications Distributed Nodes:
2x 12-Core Intel Xeon 6126
Disabled Hyperthreading
Disabled security mitigations
Driver: intel_pstate
disabled all C-states >= C1
active C0/P0-state
Permanent Boost-Clocks on all cores:
(scalar parallel code) 3.250 MHz
(vector parallel code, AVX2) 2.900 MHz
(vector parallel code, AVX512) 2.300 MHz
\(FLOPs_{node} = 1.77 \text{ TFLOPs}\)
12x 16 GB = 192 GB RAM (182 GB RAM usable for computation)
DDR4 2666 MT/s, Dual-Rank (NUMA balanced)
512 GB NVMe SSD
1x10 Gbit LAN (Distributed File System, Management)
1x100 Gbit OPA (MPI)
\(R_{max} = FLOPs_{all nodes} = 28.26 \text{ TFLOPs}\)
OS-System
Benchmarks
The following benchmarks are specific for the distributed nodes, since they are concerned with MPI efficiency.
linpack (HPL) REF: \(R_{peak} = 22.99 \text{ TFLOPs}\), which means the cluster has an efficiency of \(81.3%\) (\(\frac{R_{peak}}{R_{max}}\)). The following configuration was used for this:
Using cblas, mpi and compiler from Intel REF [3]
Launching the problem with mixed MPI and OpenMP instead of using only MPI.
Partition linpack into 16x2 parts (reflecting the number of nodes and sockets per node). Each MPI-process spawns 12 OpenMP threads.
Inter-communication between different sockets and nodes is done via MPI, intra by OpenMP.
Using Omni-Path libraries also for OpenMP-communication
Process a block size (\(\text{NB}\)) of 384 double-value entries in one loop.
Using a problem size (\(\text{N}\)) of 594432 (equals 1548x block size, max. amount of memory allocated over the whole cluster)
Calling procedure
mpirun -genv I_MPI_FABRICS shm:ofi -genv PSM2_BOUNCE_SZ 8192 -genv OMP_NUM_THREADS=12 -perhost 2 -hostfile ${HOST_FILE} -np 32, where the host file contains the information about the 16x2 partition.
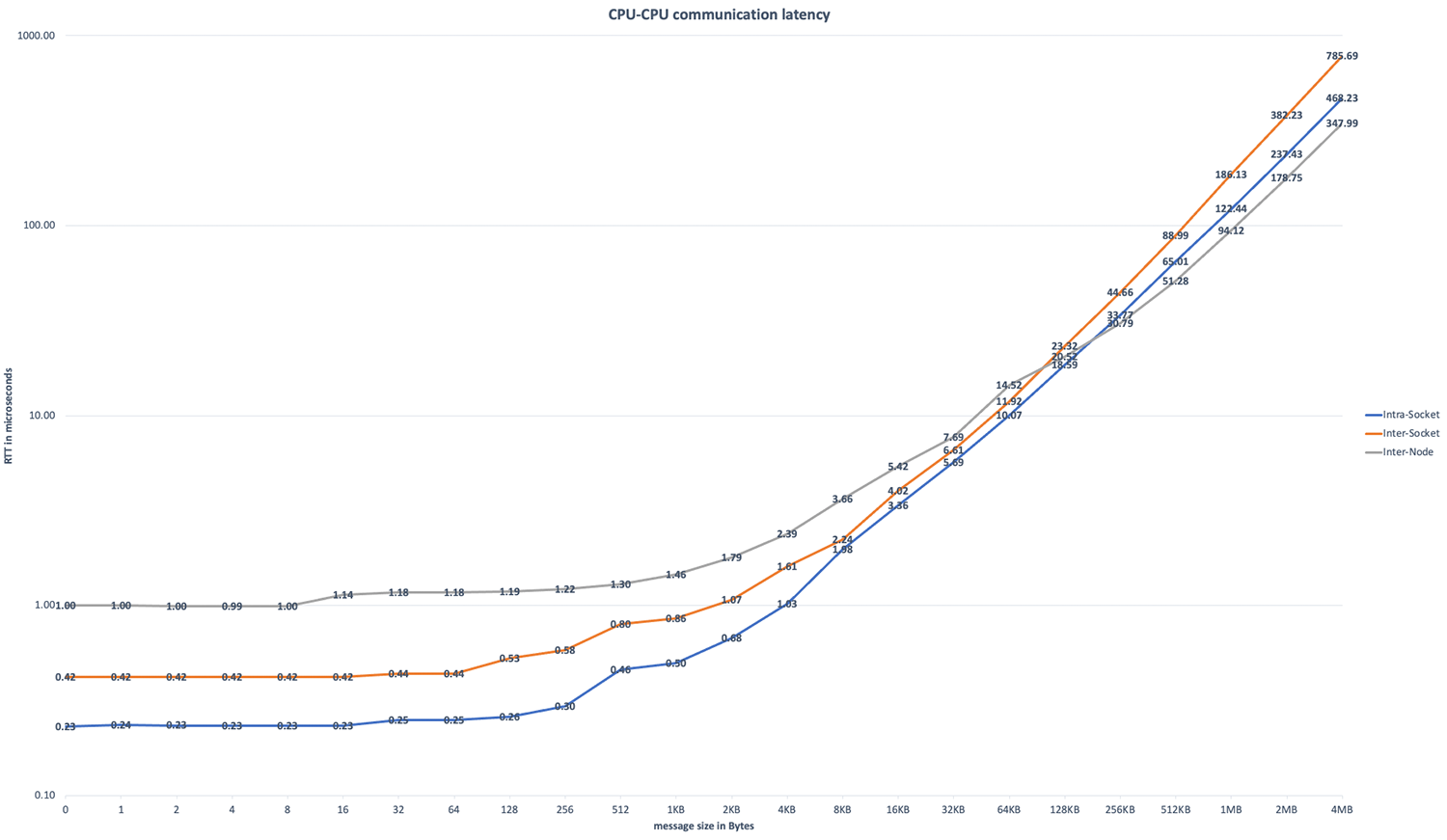
CPU-Communication Latency: Measurements include communication latencies for core-to-core communication with varying package sizes in three different scenarios:
Both cores are on the same socket (NUMA node 0). This accounts for intra-socket communication.
Both cores are on the same node, but different socket. This accounts for the delay in inter-socket (UPI) communication.
Both cores are on different nodes, but on the same socket (NUMA node 0). This accounts for the delay in inter-node (OPA) communication.
Calling procedure:
I_MPI_DEBUG=4 mpirun -n 2 -ppn 1 -genv I_MPI_PIN_PROCESSOR_LIST=$pin1,$pin2 -iface ib0 -hosts $i,$j -genvall -verbose ./IMB-MPI1 pingpong -off_cache -1, where pin1/pin2 and i/j sets the core and node pinning.IMB-MPI1is part of the Intel MPI benchmarking suite [4]. The tests using RTT from a single MPI message pair.
Notes
Formula for FLOPs (floating point operations per second) calculation: \(FLOPs_{node} = \frac{FLOPs}{cycle} \times f_{avx512} \times S \times C\)
\(\frac{FLOPs}{cycle}\) is calculated by \(\frac{vector-width}{variable-width} \times num_{\text{ FMA units}} \times num_{\text{ FMA-ops per cycle}}\). Since both (SHM + Distributed) nodes share the same architecture and feature-level, \(\frac{FLOPs}{cycle} = \frac{512}{64} \times 2 \times 2 = 32\).
\(f_{avx512}\) is the maximum frequency under full vectorization.
\(S\) is the number of sockets.
\(C\) is the number of cores per socket.